
-
お電話でのお問い合わせ050-5876-8769
- お問い合わせ
お電話でのお問い合わせ050-5876-8769

アクセス解析を始めると、まず気になるのはアクセス数です。記事を公開したら、どのくらいアクセスがあるかと頻繁にGoogleアナリティクスを見ている管理者も少なくないでしょう。
サイトを立ち上げた間もない頃はアクセス数が増えませんし、時間が経っても一般的なサイトではなかなかアクセスが増えないのが実情です。そんな中で、あるとき急にアクセスが増えたらどうでしょうか。ようやく認知されたか、と思うのは早計です。
明確な原因がないのに急にアクセスが増えるというのもおかしな話で、ほとんどの場合はリファラースパムという迷惑行為によるアクセスです。
Googleアナリティクスでは、ユーザーを獲得した手段をチャネルと呼び、Direct、Organic Search、Referral、Socialなど9種類が用意されています。
リファラースパムは、他のサイトを経由してアクセスしてきたことを示すReferralに現れます。その目的は、アクセス元として記録されている自分のサイトへアクセスを誘導することです。アクセス解析している人が、どんなサイトを経由してユーザーが来たかと興味をもって、自分のサイトへアクセスしてくることを期待している訳です。誘導される先は、通販サイトや、ウィルスなどのマルウェア(害を及ぼすソフトウェア)の配布元です。不用意にアクセスして、マルウェアの被害に遭わないように注意が必要です。
リファラースパムの仕組みを説明する前に、通常、Googleアナリティクスのデータがどのようにしてサーバーに格納されるか見てみましょう。
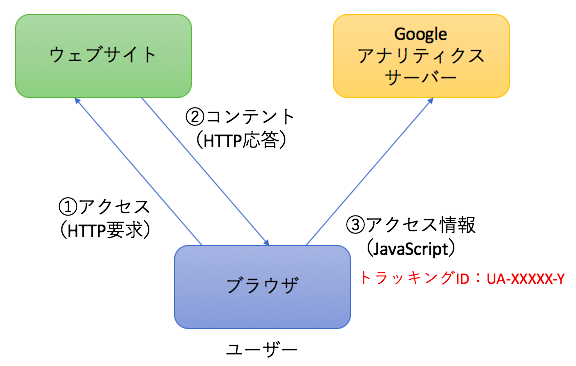
上図のように、①ユーザーがアクセスすると、②ウェブサイトからコンテント(ページの内容)が返されます。コンテントの中には、JavaScriptで記述されたプログラムがあり、ブラウザで実行して③トラッキングIDやページの情報をGoogleアナリティクスのサーバーに送ります。トラッキングIDは、アクセス解析をする対象を識別するための情報で、UA-XXXX-Yという形式になっています。XとYは数字です。
リファラースパムの仕組みにはいくつかありますが、分かりやすいのはクローラーによるスパムです。クローラースパムでは、検索エンジンがインデックスを作成するために用いるクローラーと同様に、実際にウェブサイトにアクセスしてきます。検索エンジンのクローラーと違って、インデックスさせないための指示であるrobot.txtを無視してアクセスしてくることもあります。クローラーが上図のブラウザと同様の動作をして、Googleアナリティクスのサーバーに情報を送ります。
リファラースパムのもうひとつの代表例が、ゴーストスパムです。ゴーストスパムは、実際にウェブサイトにアクセスすることはなく、Measurement Protocolという、Googleアナリティクスのサーバーへデータを格納するための通信方式を使って、偽のデータを送り込んで来ます。Measurement Protocolでデータを送信する目的は、ゲーム機など、ブラウザ以外からもアクセスデータを格納できるようにするためです。
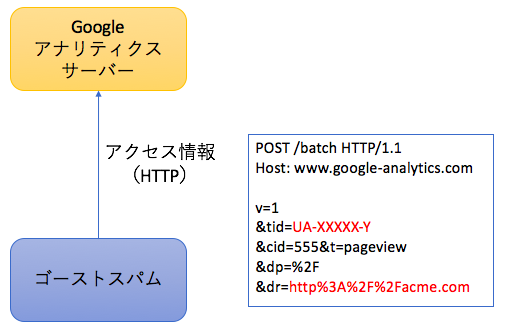
ゴーストスパムは、クローラーと違って、実際にウェブサイトにアクセスすることはありません。上図で四角で囲んだ文字列は、アクセス情報として登録される内容です。ここでは、トラッキングIDと参照元のドキュメント(URL)に注目してください。%3Aはコロン(:)、%2Fはスラッシュ(/)を表すので、参照元はhttp://acme.comとなります。
ウェブサイトにアクセスせずにトラッキングIDをどうやって入手するのかと不思議に思われるかもしれませんが、ゴーストスパムは実際には入手しておらず、適当に生成した文字列を指定します。ですから、どのサイトに対して偽のデータを送り込んでいるか分かっていないのです。これが、後述する対策が機能する理由です。
Googleアナリティクスのフィルタを使うと、解析結果からリファラースパムを除去することができます。スパム対策は、基本的に参照元のホスト名を使って除外します。
しかし、この対策の問題点は、参照元ごとにフィルタを用意しなくてはいけないことです。リファラースパムは日々増えていますので、サイト管理者は常に参照元に注意を払い、新たなリファラースパムに対してフィルタを定義し続けなくてはなりません。
スパマーにとっては都合のよいゴーストスパムでは、トラッキングIDは適当に作成していますから、どのサイトに偽の情報を送っているか分かっていません。HTTP要求ではアクセス先のホスト名を指定することが必須になっていますが、アクセス先が分かっていないので、ホスト名を指定していないか、正しくないホスト名を指定しています。
このことを利用して、以下のようにフィルタを設定します。
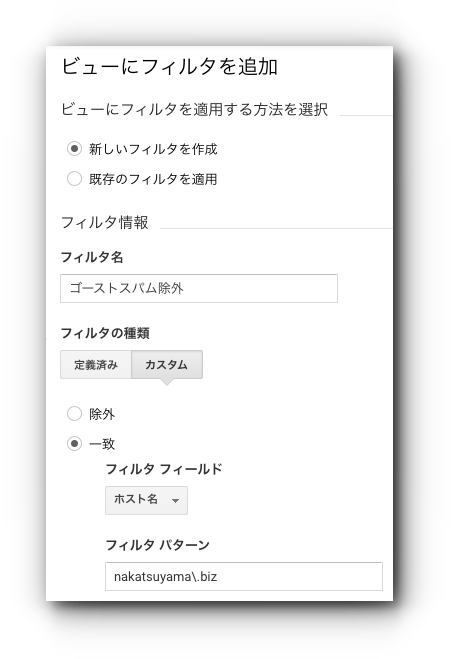
お詫び
当初の記事では「除外」フィルタとしていましたが、正しくは「一致」フィルタです。お詫びして訂正いたします。
設定でお悩みになった方には、大変申し訳ありません。
このフィルタは本サイトで実際に指定している設定で、これだけでリファラースパムを一網打尽にしています。言い換えると、ホスト名を正しく指定しているリファラースパムは、本サイトのデータには今のところはないということになります。
なお、フィルタパターンでピリオド(.)の前にバックスラッシュ(\)があるのは、ピリオドが任意の1文字とマッチする特殊文字なので、ピリオド自体を表すためです。フィルタパターンでは複数のパターンを指定することができ、その場合は縦棒(|)をパターン間に置きます。








